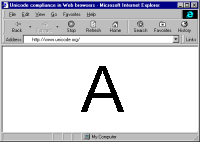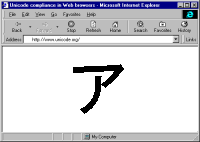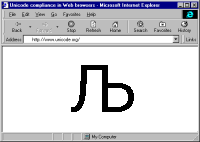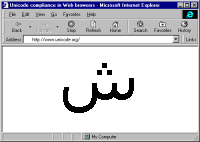
Alan Wood’s Unicode resourcesUnicode and multilingual support in HTML, fonts, Web browsers and other applications
Caution and apologyI regret that I no longer have the time to keep this website up-to-date. The test pages include the Unicode 6.3 characters, and some of the Unicode 7.0 characters, but nothing more recent. The pages of fonts and utilities have not been updated for several years. IntroductionBefore Unicode became widely supported, it was not uncommon to face problems such as trying to include a passage in a different alphabet in one of your documents, for example a quotation in Russian in an English document, only to find that you had no Cyrillic characters available. Or to send a Spanish document in electronic form to someone in Greece, only to be told that the accented Latin characters had been replaced by Greek characters. Or to produce a Web page that included technical symbols and found that it worked with Windows but not with Mac OS or Unix. Problems like these arose with non-Latin alphabets and Symbol font because in those days most computers used fonts that contained a maximum of 256 characters. The first 128 characters (the ASCII characters) of most fonts included punctuation marks, numbers and the letters a–z and A–Z, and were not a problem. In the USA, Canada, the United Kingdom, the rest of the English-speaking world and much of Western Europe, the second set of 128 characters comprised more punctuation marks, some currency symbols (such as £ and ¥) and a lot of accented letters (such as á, ç, è, ñ, ô and ü). Older English versions of Microsoft Windows, and several other language editions, used this set of 256 characters, which is known as the ANSI character set. If you lived in a country such as Egypt, Greece, Israel, Russia or Thailand that uses a different alphabet, then your version of Windows used a different character set. The first 128 characters were the same as in ANSI, but many of the places in the second set of 128 were taken by characters from the Arabic, Greek, Hebrew, Cyrillic or Thai alphabets. When documents started to be transferred electronically as e-mail messages, e-mail attachments or Web pages, instead of on paper, reading documents from another country, particularly a country with a different alphabet, became more and more of a problem. There were similar problems when moving documents between operating systems such as DOS, Windows, Mac OS and UNIX. The solution was to leave behind the assortment of 8-bit fonts with their limit of 256 characters, where the same character number represented a different character in different alphabets, and move to a system that assigns a unique number to each character in each of the major languages of the world. Such a system was developed and is known as Unicode. It is intended for use on all computer systems, not just Windows, and covers Chinese, Japanese and Korean as well as the alphabets for many other languages and scripts, plus a large number of special characters. Some Unicode support has been included in Microsoft Windows since Windows 95, and Windows NT 4, Windows 2000, Windows XP, Windows Vista, Windows 7 and Windows 8 are based on Unicode instead of the ANSI or WGL4 character sets. Some Unicode support has been included in Mac OS since Mac OS 8.5, but prior to Mac OS X 10 only limited use was made of it by applications. Unicode is sometimes referred to as a 16-bit system, which would allow for only 65,536 characters, but this is not correct, and Unicode has the potential to cope with over one million unique characters. The current version (6.3.0) of the Unicode Standard, developed by the Unicode Consortium, assigns a unique identifier to each of 110,187 graphical, formatting and control characters, covering the scripts of the world’s principal written languages and many mathematical and other symbols. A previous version (2.1) of the Unicode Standard encompassed 38,887 characters and was adopted as part of the recommendations for HTML 4.0.
On this Web site, I have tried to gather together practical information about Unicode and the increasing number of applications and fonts that support it, intended to help people who are trying to use Unicode to produce standardised multilingual and technical documents. The pages on the site include:
For a complete list of pages on the site, please see the Site Map. Test pages for Unicode character rangesThe pages in the following list can be used to display the ranges of characters defined in the Unicode 6.3.0 Character Database, within the limitations imposed by your Web browser and the fonts that you have installed. There is also a page with a sample of Unicode characters from each range. Web sites of other Unicode proponents
Copyright © 1999–2016 Alan Wood
|